Earth Notes: On Website Technicals (2019-10)
Updated 2025-04-19.: Transcript using Audacity
Yesterday, Adam was guest on a podcast episode. (Thank you Adam.)
Normally I script the episode, intermingled with whatever goodies such as code or sounds are part of the topic. Then I read the script into Audacity and start to edit the sound.
I still did that with the top and tail of the piece, but the bulk of it was not pre-scripted: Adam ad-libbed into Audacity.
So I edited out coughs etc. Then manually transcribed the approximately 5 minutes of Adam over the course of a couple of hours. (Some of which was spent perched on the sofa of a Radbot ECO3 trialist that I was visiting, while waiting for a taxi!). I used Audacity to play circa 5 to 10 seconds at a time, as often as needed, to type the words.
Some helpful features of Audacity for this task:
- The ability to see silence/pauses, and so visually select clean phrases to transcribe at once.
- The ability to easily replay the same exact section over and over.
- The clearly marked start and end times of such sections, which makes it easy to put timestamps in the transcript, for example.
: PodcastEpisode
Woot! schema.org 4.0 seems to have just gone live including a well-overdue PodcastEpisode type. All my episodes are now a mix-in of BlogPost and this new type.
I will in due course make the podcast section page a PodcastSeries mix-in and add the RSS webFeed etc. And I will have the episodes link back to it with partOfSeries rather than just the current partOf.
Auto-abstract
Also, supporting my attempt to write a content pyramid, I am now marking all the 'pgintro' text with the new abstract itemprop. I may have to revisit and tweak some of the content, but a sampling looks satisfactory for some interpretations of what an 'abstract' is.
: Podcast Rash
There has been a small outbreak of audification podcasts such as How Does PV Grid-tie Generation Sound in Time-lapse?, because it has been fun!
It seems very hard to tell when anyone is actually listening since at least Apple and Google seem to cache the .mp3 files to play to end users.
At least some of the services polling the RSS feed do not seem to know how to do If-Modified-Since or similar. This may prove to be a nuisance as the file gets bigger. I could also apply compression, possibly statically, to help in some cases. But the bandwidth is trivial for now.
: Automating Archiving
I put some extra effort into datasets last month, since GSC (Google Search Console) started reporting on issues with them. GSC wanted encodingFormat and license on everything.
In passing to enable the later, I made everything CC0, ie effectively public domain, per Andrew Katz' advice.
I also converted everything from JSON-LD to HTML5 microdata to make it visible to a reader of the page, and to reduce the chance of getting metadata out of sync from any HTML natural-language description. This also lets me make the microdata part of the same page metadata as everything else, rather than floating unattached.
This flies in the face of Google's preference for JSON-LD. But microdata works better for EOU I think.
Currently I am trying to save myself some of the monthly chore of making consolidated/compressed/archive batches available by scripting the work, and by driving the script from cron on the first of every month.
: hurrah, it seems to have worked; when I do an svn commit I see:
Adding (bin) data/16WWHiRes/Enphase/201910.daily.production.json.gz Adding (bin) data/16WWHiRes/Enphase/201910.log.gz Adding (bin) data/OpenTRV/pubarchive/localtemp/201910.log.gz Adding (bin) data/OpenTRV/pubarchive/remote/201910.json.gz Adding (bin) data/RPi/cputemp/201910.log.xz Adding (bin) data/SunnyBeam/201910.gz Adding data/WW-PV-roof/raw/sunnybeam.dump.20191014.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191015.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191016.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191017.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191018.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191019.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191020.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191021.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191022.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191023.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191024.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191025.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191026.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191027.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191028.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191029.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191030.txt Adding data/WW-PV-roof/raw/sunnybeam.dump.20191031.txt Adding (bin) data/powermng/201910.log.gz
: GSC Enhancements
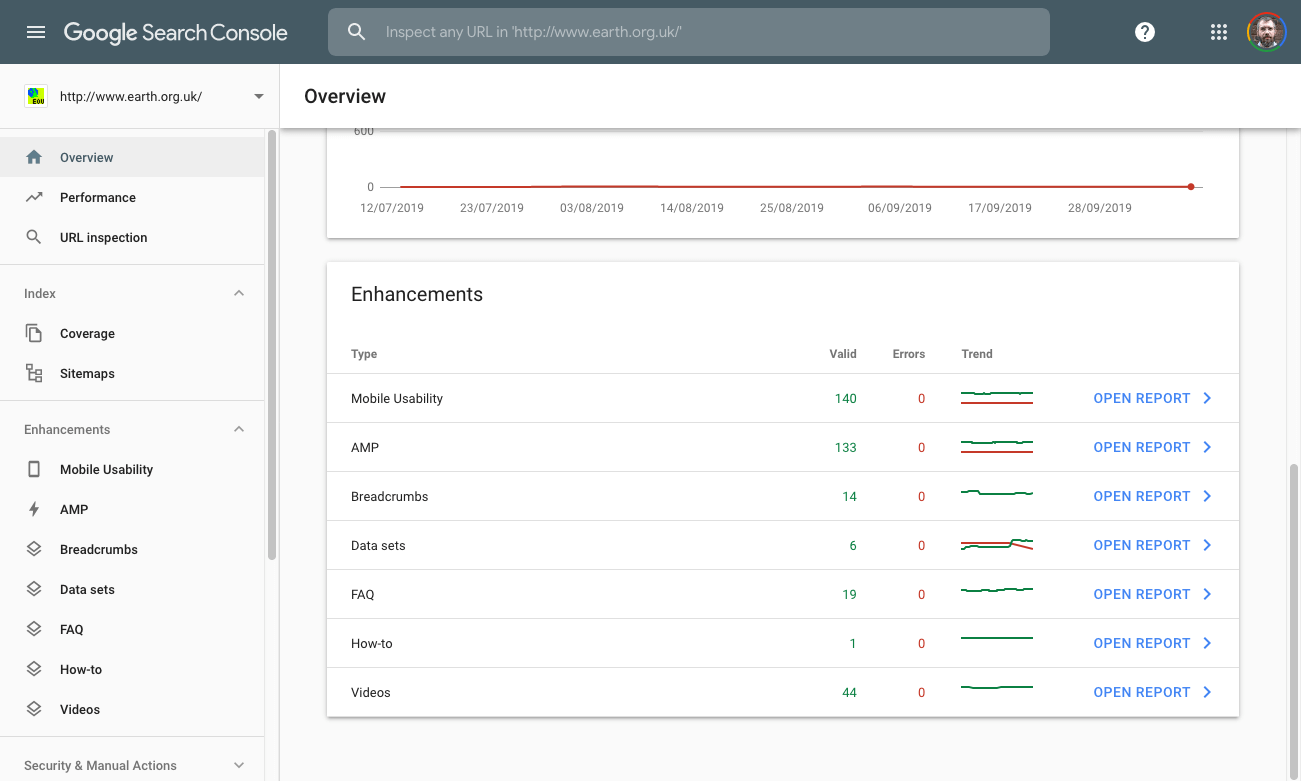
Google is adding more stuff (eg structured-data related) to the "Enhancements" part of its Search Console, the latest being videos. I did not know that I had so many!
I still do not like the 'Valid' legend, since not all candidates are shown, yet there are no errors reported, so things not 'Valid' are clearly not 'Invalid'. They seem to be things that Google is not currently interested in indexing. Also interesting, but not at all the same.