Earth Notes: On Website Technicals (2019-03)
Updated 2025-04-07.schema.org semantic markup where possible, preferably automatically from information implicitly known by the system. Sharing is caring!: DefinedTermSet
The glossary is now a DefinedTermSet and a FAQPage (a floor wax and a dessert topping?) in the hope that search engines can understand it now as a FAQPage and in future more precisely as a DefinedTermSet.
I also now have pages in a series link back to the series head/root with isPartOf.
: HTTP vs HTTPS
Today's flash of inspiration to avoid having six different versions of EOU in operation, yet support very-low-bandwidth and non-HTTPS users, is to keep m./lite on HTTP (1.1), but switch www./desktop and amp./AMP to HTTP/2 over https. The default/canonical (desktop) would therefore be responsive and secure, which should make Google and others happy.
: MachMetrics etc
Sunday: just the bright and sunny day to add more schema.org markup* to EOU, write up teaching Year 4 about circuits and solar power, and to say thank you to MachMetrics for their (free) speed-monitoring tools that I use with EOU.
It's been a busy wordsmithing weekend, somehow...
* Mainly sdUpdated, though a little time jiggery-pokery elsewhere too!
: Glossary
I started a site glossary!
I failed to get it to straightforwardly fit both I don't think that Google uses Question/Answer and DefinedTerm schemas at once for now. So it's officially a FAQPage and not a DefinedTermSet. DefinedTerm yet, and I suspect that no one else does either, so I will revisit unhurriedly...
: BlogPosting
I claim that I have never blogged in the vanilla sense, eg about what I ate for breakfast, and other (non-tech) trivialities.
However, for the sake of schema.org have I switched a bunch of pages from a plain Article type to BlogPosting. It's like a confession, with fingers crossed behind my back.
: Page Overhead
Just measured for a typical desktop page (source ~17kB), all the text outside the main tags is ~6kB, or ~2kB after gzip. Wheww!
A quick survey of precompressed desktop-page size suggests most can still be fully sent in the initial TCP window of 10x 1460-byte frames with a few hundred (~300) bytes for HTTP (1.1) headers:
% ls -alSr *gz | wc -l
213
% ls -alSr *gz | awk '14000>$5{print}' | wc -l
174
: AMP - Image size smaller than recommended size
Having wrapped all body images in ImageObject I now see (three) complaints under the AMP section of Google Search Console stating "Image size smaller than recommended size", though the inspection tools are being a bit coy about exactly what the issues are, eg is there more than one undersized image on any of the three flagged pages? Which actual images even?
This ImageObject wrapping in general seems to be worth persisting with since in the Google Structured Data Testing Tool, I am starting to see search previews with embedded images as hoped.
Should the ImageObject wrapper maybe be omitted for smaller images? That seems somewhat Google centric, especially as the 'smaller' images are still much bigger than appear in the search previews! Nominally Google wants only raster images of type JPG/PNG/GIF that are also at least 1200w and 800k pixels, at least for AMP.
The schema.org/Thing documentation describes the image field as:
An image of the item. This can be a URL or a fully described ImageObject.
So maybe body images which are merely used in discussing the main subject of an article but are not "of" it by some criteria, should avoid an ImageObject wrapper. Signalling that might require a pseudo attribute on the IMG tag for example.
It would probably be sensible to let Google spit out a few more results and warnings before starting to fiddle with things, especially as a full recrawling cycle may be several weeks for top-level pages that Google has currently excluded from its index.
... However, I am going to remove the ImageObject wrapping from body images and instead insert appropriately cropped versions of the page's hero images as ImageObject instances, to try to help the SEs, given that those images are definitely intended to be 'representative'.
(Update : though with prodding it pulled through a few (~8) almost immediately, I can now see Googlebot-Image starting to fetch some of the new crafted-aspect-ratio hero images only mentioned in links in the ImageObjects in the page footer and invisible to a human reader. This is not hidden content, as these are only trivial variants of the hero images that the user can see, for example. Nothing else appears to be fetching the new images at all.)
(Update : GSC today reports the issue as cleared.)
: Making Heroes representativeOfPage
As an experiment I am adding markup to all the hero ImageObject items to make them "representativeOfPage" in the hope that that helps them appear in the SERPS alongside snippets.
For all body images I am also marking them up as ImageObject, with the URL pointing at the highest-resolution version of the image available, typically the original. That may be much higher than would normally be shown in the page. Again, the hope is that helps search engines add a thumbnail to any search result.
: Allowing Embedded BlogPosting
To give search engines a chance to pick out individual posts, and indeed to allow them to be assembled automatically into pages, I have added support to the page build and marked up a couple here.
That support includes the ability to refer to the page's author, publisher, image, etc, by reference (itemref) rather than repeating them. A fair amount of constant boiler-plate is still required, reducing the savings from that referencing. But reducing the risk of clerical errors is still good.
(Hat tip for worked examples to HTML5 Microdata - itemref to another itemscope (Person works for Organization)
.)
Note that where a constituent/embedded blog posting has its own image, that could nominally be used rather than the page's.
By the same token, a guest author could be specified if necessary.
The embedding should work for any CreativeWork.
: Swing of Traffic from M-dot
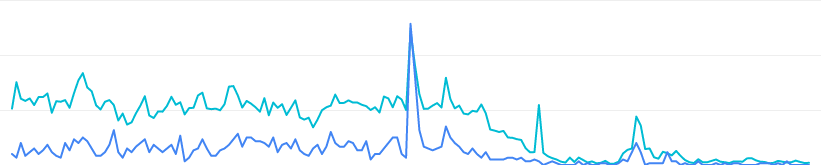
See the 6-month traffic chart (old-style, hits not attributed to the canonical URL), to . AMP versions of pages started going up about Christmas Eve, ie just over half-way through. Note that m-dot traffic takes a dive on the Christmas weekend a couple of days before the first AMP pages started actively sucking traffic away...
(The small resurgence of traffic late Jan was about the time that Google had an AMP glitch and complained about and deindexed lots of AMP, setting SEO social meeja alight!)
: FAQ Mix-in
I have made it possible to "mix in" a schema.org/FAQPage type with a normal page type, by adding a 'FAQ' tag.
This allows me to embed one or more Questions (and nested Answers) without getting warnings from Google's Structured Data Testing tool.
I am hoping that this improves the snippets that Google (and other search engines) can extract from my pages...
Hat-tip to "Schema.org for the FAQ page
" for pointing out that the itemtype can have multiple values!
I have also managed to automatically insert some new schema.org metadata, such as timeRequired, and position (of Article in series), and temporalCoverage.
Note to self: test structured data with at least one other tool than Google's, eg Yandex has one with a slightly different view. Yandex, for example, points out that when a tag target/content is a URL then link should be used in place of meta.
- Google's Structured Data Testing Tool.
- Yandex' Structured data validator.
: Double GZip Compression
I have been feeling slightly nervous that I might have been attempting to re-compress my pre-compressed .htmlgz files in Apache's mod_deflate.
To allay that fear I tweaked appropriate lines in Apache's config from:
RewriteCond %{HTTP:Accept-Encoding} gzip
RewriteCond %{DOCUMENT_ROOT}%{REQUEST_FILENAME}gz -s
RewriteRule ^/(.+)\.(html|css|js|xml)$ /$1.$2gz [L]
to:
... RewriteRule ^/(.+)\.(html|css|js|xml)$ /$1.$2gz [E=no-gzip:1,L]
TTFB for a local request appears to be ~10ms even for a 45380-byte .htmlgz file, so I am probably not attempting a double!
: 403 Log Clutter
It's a bit sad that tens of thousands of hits on my site last week were of this form (excerpt from log, perp's IP address removed):
- - [02/Mar/2019:11:05:02 +0000] "GET /out/hourly/button/intico1-48.png?rand=1551524689968 HTTP/1.1" 403 441 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36" - - [02/Mar/2019:11:05:18 +0000] "GET /out/hourly/button/intico1-48.png?rand=1551524705968 HTTP/1.1" 403 441 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
That is, someone trying to cache-bust every few seconds to get a refresh of an image which updates at most once every 5 minutes (typically every 10 minutes). And my documentation asks people not to do this.
I originally had the cache bust attempt redirect to the original, but after months of that not changing behaviour, I now have it result in "Forbidden" (403). So these fetches have yielded nothing but failure for months, but no one has noticed. That's a substantial fraction of all traffic and a lot of clutter in my logs for nothing at all. And a literally a waste of (off-grid) energy...
Annoying.
(Update : almost all my traffic is this, plus Applebot fetching some long-since-redirected URLs over and over for another site... Grrr... Though Apple did respond to a bug report after a few days and stop!)